How do I find robots txt?

Testez vos robots. fichier txt
- Ouvrez l’outil de test pour votre site et faites défiler les robots. …
- Saisissez l’URL d’une page de votre site Web dans la zone de texte en bas de la page.
- Dans la liste déroulante à droite de la zone de texte, sélectionnez l’agent utilisateur que vous souhaitez simuler.
- Cliquez sur le bouton TEST pour tester l’accès.
Où est mon fichier txt de robots ? Un robot. txt se trouve dans le répertoire racine de votre site. Ainsi, pour le site Web www.example.com, le fichier robots. txt se trouve à l’adresse www.example.com/robots.txt.
What if a website doesn’t have a robots txt file?
Robot. txt est complètement facultatif. Si vous en avez un, les robots d’exploration conformes aux normes le respecteront, si vous n’en avez pas, tout ce qui n’est pas autorisé dans les éléments HTML META (Wikipédia) est explorable. Le site est indexé sans restrictions.
How do I get a robots txt file from a website?
Les robots seront toujours à la recherche de vos robots. txt dans le répertoire racine de votre site Web, par exemple : https://www.contentkingapp.com/robots.txt. Accédez à votre domaine et ajoutez simplement « / robots. Txt ».
Does every website have a robots txt file?
Non, un robot. txt n’est pas requis pour un site Web. Lorsqu’un bot arrive sur votre site Web et n’en a pas, il va simplement explorer votre site Web et indexer les pages comme d’habitude.
Does every website have a robots txt file?
Non, un robot. txt n’est pas requis pour un site Web. Lorsqu’un bot arrive sur votre site Web et n’en a pas, il va simplement explorer votre site Web et indexer les pages comme d’habitude.
Does my site have robots txt?
Trouvez votre robot. txt dans le répertoire racine de votre site Web, par exemple : https://www.contentkingapp.com/robots.txt. Accédez à votre domaine et ajoutez simplement « / robots. Txt ». Si rien ne vient, vous n’avez pas de robot.
Do all web robots follow robots txt file?
Les instructions txt peuvent ne pas être prises en charge par tous les moteurs de recherche. Les instructions dans robots. les fichiers txt ne peuvent pas forcer l’exploration de votre site ; C’est au crawler de leur obéir. Alors que le Googlebot et d’autres robots d’exploration Web réputés suivent les instructions d’un robot.
What is screaming frog good for?
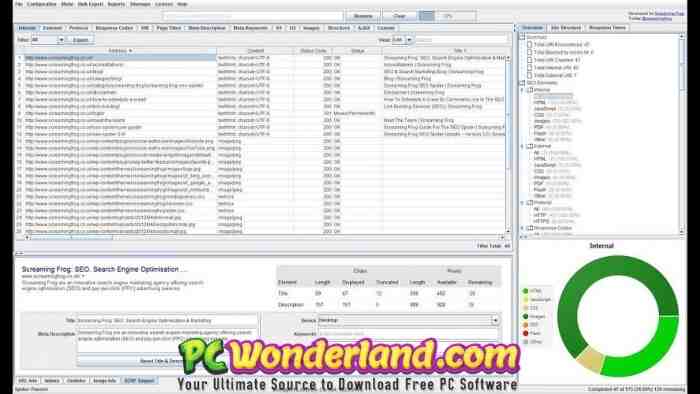
Le Screaming Frog SEO Spider est un outil d’audit de site SEO rapide et avancé. Il peut être utilisé pour explorer des sites Web petits et très grands où l’examen manuel de chaque page serait extrêmement laborieux et vous pouvez facilement manquer une redirection, une méta-mise à jour ou un problème de page en double.
Que fait une grenouille qui crie ? Outil SEO Spider Le Screaming Frog SEO Spider est un robot d’exploration de site Web qui vous aide à améliorer votre référencement sur le terrain en extrayant des données et en vérifiant les problèmes de référencement courants. Téléchargez et explorez gratuitement 500 URL, ou achetez une licence pour supprimer la restriction et accéder aux fonctionnalités avancées.
Is Screaming Frog good?
Screaming Frog est notre outil d’audit de choix lorsque vous examinez pour la première fois un nouveau projet potentiel. Même la version gratuite de Screaming Frog est très utile. Il est utilisé à l’échelle de l’entreprise et constitue le moyen le plus rapide que nous ayons trouvé pour avoir un bon » aperçu » de la santé d’une page d’un site.
Why is it called Screaming Frog?
2010 : Le début de quelque chose que Big Dan poursuit, est à la recherche d’un nouveau défi passionnant et commence à travailler à temps plein en tant que consultant SEO sous le nom de « Screaming Frog ». Le nom Screaming Frog est inspiré d’une grenouille qui s’est défendue après avoir été coincée par deux chats dans le jardin de Dan.
How do you save a screaming frog?
Enregistrez et ouvrez en mode de sauvegarde le type de fichier seopider spécialement pour Screaming Frog SEO Spider. Vous pouvez enregistrer les crawls entre les deux en interrompant le SEO Spider ou à la fin d’un crawl en sélectionnant ‘Fichier> Enregistrer’.
Why is it called Screaming Frog?
2010 : Le début de quelque chose que Big Dan poursuit, est à la recherche d’un nouveau défi passionnant et commence à travailler à temps plein en tant que consultant SEO sous le nom de « Screaming Frog ». Le nom Screaming Frog est inspiré d’une grenouille qui s’est défendue après avoir été coincée par deux chats dans le jardin de Dan.
What is the screaming frog called?
| Lepidobatraque | |
|---|---|
| Classer: | Amphibiens |
| Commander: | Anoure |
| Famille: | Ceratophryidae |
| Genre: | Lepidobatrachus Budgett, 1899 |
What does Canonicalised mean in screaming frog?
Canonisée – « La page a une URL canonique qui est différente de celle-ci. L’URL est « canonisée » dans un emplacement différent. Cela signifie que les moteurs de recherche ont pour instruction de ne pas indexer la page et que les propriétés d’indexation et de liaison doivent être consolidées avec l’URL canonique cible.
How do you limit the speed of a screaming frog?

Augmenter la vitesse d’exploration de la grenouille hurlante Pour gagner du temps, augmentez la vitesse d’exploration dans l’onglet Configuration. Une fois que vous avez cliqué sur Vitesse, la boîte de dialogue Configuration de la vitesse Spider apparaît. Le côté de « Max. Le nombre de threads détermine la vitesse à laquelle vous pouvez explorer un site Web.
Quel est le temps de réponse de Screaming Frog ? Délai de réponse – « Le temps que l’araignée SEO attend une réponse d’une URL est désormais configurable, ce qui est utile pour les sites Web à chargement très lent. Nouveaux filtres – « Nous avons introduit de nouveaux filtres, tels que les titres de page de moins de 30 caractères ou les méta-descriptions de moins de 70 caractères.
How do you exclude parameters in screaming frog?
Tout d’abord, cliquez sur le menu de configuration et naviguez dans le menu déroulant. Cliquez ensuite sur la configuration « Exclure ». Ensuite, vous utiliserez Regex pour indiquer au robot quel dossier vous ne souhaitez pas explorer. Vous trouverez ci-dessous le dossier que je souhaite exclure de mon Screaming Frog Crawl.
What does non indexable mean in Screaming Frog?
Selon Screaming Frog, un statut d’indexation d’URL non indexable peut être attribué à l’un des problèmes suivants. Les URL : sont bloquées par les robots. SMS. Ne donnez pas de réponse.
How do you use custom search on Screaming Frog?
Dans le menu de niveau supérieur, cliquez sur Config> Custom> Search pour ouvrir la configuration de recherche personnalisée. Cliquez ensuite sur « Ajouter » (en bas à droite) pour configurer un filtre de recherche personnalisé. Un filtre de recherche personnalisé s’affiche. Vous pouvez ajouter jusqu’à 100 filtres distincts en une seule analyse.
Why is screaming frog only crawls one page?
Raison : si elles sont définies sur 0 ou 1, l’araignée SEO est chargée de n’explorer qu’une seule URL. A vérifier : le site a-t-il besoin de cookies ? (Afficher la page dans le navigateur avec les cookies désactivés). Essayez-le : Configuration > Spider > onglet Avancé > Autoriser les cookies.
How do you crawl multiple URLs in screaming frog?
Accédez à « Config> Spider> Crawl ». Décochez tous les « Liens de ressources » et « Liens de page » dans le menu de configuration pour « Explorer ». Ensuite, à côté de votre liste d’URL, sélectionnez les éléments que vous souhaitez « explorer ». Par exemple, si vous vouliez parcourir la liste des URL et leurs images, voici comment se déroulerait la configuration.
How does a screaming frog crawl a website?
Utilisez Screaming Frog pour identifier tous les sous-domaines d’un site donné. Accédez à Configuration> Spider et assurez-vous que « Rechercher dans tous les sous-domaines » est sélectionné. Tout comme l’exploration de l’intégralité de votre site ci-dessus, cela aidera à explorer tout sous-domaine lié à l’exploration du site.
How do you check breadcrumbs in screaming frog?

Pour tester dans Screaming Frog, sélectionnez « Entrer manuellement » dans les options de téléchargement. Ensuite, fournissez simplement une URL de produit. Lorsque j’ai testé cela pour la première fois, toutes les colonnes d’extraction personnalisées étaient vides – elles ont été générées dynamiquement à l’aide de JavaScript. Pour résoudre ce problème, sélectionnez « JavaScript » sous « Rendu » dans la configuration.