Comment utiliser Scrapy ?
Sur la ligne de commande Scrapy, créez tous les fichiers supplémentaires nécessaires à la construction du projet (comme Django). Enfin Scrapy est très rapide et peut numériser des dizaines de pages à la fois. De plus, il est possible d’améliorer la vitesse du texte ou d’autres paramètres.
Pourquoi le Web est-il rayé ? L’objectif principal de l’exploration Web est de pouvoir compiler du contenu sur le Web, qui peut être copié et collé sans déformer la structure du document. Cette technique est donc souvent utilisée dans le cadre de secrets concurrentiels, notamment dans les sites de commerce électronique.
Comment scraper Python ?
Voici les étapes clés pour explorer votre site à l’aide de Python :
- Trouvez l’URL du site à gratter.
- Naviguer sur la page
- Trouvez les données que vous souhaitez extraire.
- Demandez un bloc-notes.
- Rédaction et traitement des données.
- Stockez les données dans le format requis.
Comment utiliser BeautifulSoup ?
Le produit BeautifulSoup peut accepter deux arguments. Le premier argument est la balise actuelle et le deuxième argument est la barre que vous souhaitez utiliser. Divers analystes sont : html. analyseur, lxml et html5lib.
Comment créer un scraper ?
Le crawl se fait en deux étapes : le téléchargement, l’analyse du code HTML d’une page et son analyse. Pour trouver le contenu du site (télécharger) il suffit de faire une application et HTTP et d’attendre la réponse (Oui c’est facile).
Comment créer un scraper ?
Le crawl se fait en deux étapes : le téléchargement, l’analyse du code HTML d’une page et son analyse. Pour trouver le contenu du site (télécharger) il suffit de faire une application et HTTP et d’attendre la réponse (Oui c’est facile).
Comment scraper des données ?
Pour accéder à ces informations, vous devez ouvrir le fichier HTML et rechercher des balises (utiliser XPath ou CSS). Un outil de grattage complet est un outil, à partir d’un ou plusieurs navigateurs Web, explorant de page en page en ouvrant les fichiers source et en récupérant ce que vous souhaitez récupérer.
Comment utiliser la méthode GET ?

Méthode HTTP GET La première variable d’url est toujours précédée d’un symbole ? tandis que d’autres précéderont la marque & amp; Les noms des variables correspondent aux propriétés nominales des objets de formulaire et aux valeurs des propriétés de valeur.
Comment utiliser la récupération php ? La méthode HTTP GET php couple la variable/valeur transmise par l’unité. La première variable d’url est toujours précédée d’un symbole ? tandis que d’autres seront précédés et marqués. Les noms des variables correspondent aux propriétés nominales des objets de formulaire et aux valeurs des propriétés de valeur.
Comment utiliser la méthode POST ?
Utilisation de la méthode POST Toutes les données d’un formulaire seront envoyées à une autre page PHP via la méthode POST et seront disponibles dans le tableau superglobal $ _POST. Pour mieux le comprendre, vous créez une page PHP appelée formulaire. php contenant un formulaire avec prénom et nom.
Comment utiliser $_ POST ?
$ _POST [‘nom’] = ‘autre’; Les données envoyées peuvent être modifiées par un utilisateur, vérifiez donc toujours les informations envoyées dans ces applications.
Comment fonctionne la méthode GET ?
La méthode GET met les données dans l’URL De cette façon, les données du formulaire seront collées dans l’URL. Il contient le nom de la page ou le texte pour insérer les données du formulaire dans une chaîne.
Quelle est la différence entre la méthode GET et la méthode POST ?
Trouver des tailles de pages Web (filtrage, tri, accès à la recherche, etc.). POST pour la transmission des données utilisateur et des données.
Quelle est la méthode d’envoi de formulaire la plus recommandée qui permet d’envoyer le plus de données ?
Utilisez la méthode mail pour envoyer les données du formulaire. Notez qu’il existe plusieurs façons d’envoyer des données de formulaire (plusieurs « méthodes »). Vous pouvez en utiliser deux : find : les données passeront par l’URL, comme nous l’avons déjà appris.
C’est quoi un get ?
La norme GET est l’une des méthodes les plus couramment utilisées dans le protocole HTTP lorsqu’une application est démarrée par un client à l’aide d’un client, tel qu’un navigateur Web.
Comment fonctionne la méthode GET ?
La méthode GET met les données dans l’URL De cette façon, les données du formulaire seront collées dans l’URL. Il contient le nom de la page ou le texte pour insérer les données du formulaire dans une chaîne.
C’est quoi un get ?
La norme GET est l’une des méthodes les plus couramment utilisées dans le protocole HTTP lorsqu’une application est démarrée par un client à l’aide d’un client, tel qu’un navigateur Web.
Quand utiliser GET ou POST ?
La principale différence entre les méthodes POST et GET est que GET transporte l’unité dans la chaîne d’URL, tandis que POST transporte l’unité dans le corps du message, ce qui rend plus sûr le transfert de données du client au serveur avec le protocole http .
Qui utilise le Web scraping ?
Le réseau de grattage peut être utilisé par les entreprises pour extraire des données relatives à leurs produits et aux produits de leurs concurrents. Les entreprises peuvent utiliser ces données pour fixer les meilleurs prix pour leurs produits en fonction des données du marché.
Comment gratter des pages Web ? Le crawl se fait en deux étapes : le téléchargement, l’analyse du code HTML d’une page et son analyse. Pour trouver le contenu du site (télécharger) il suffit de faire une application et HTTP et d’attendre la réponse (Oui c’est facile).
Qui utilise le scraping ?
Le crawling Web est utilisé par de nombreuses entreprises numériques dédiées à la collecte de données. Pour mieux définir ce qu’est l’exploration Web, vous devez savoir quels sont les cas d’utilisation légitimes : les robots des moteurs de recherche explorent le site, analysent son contenu, puis le classent.
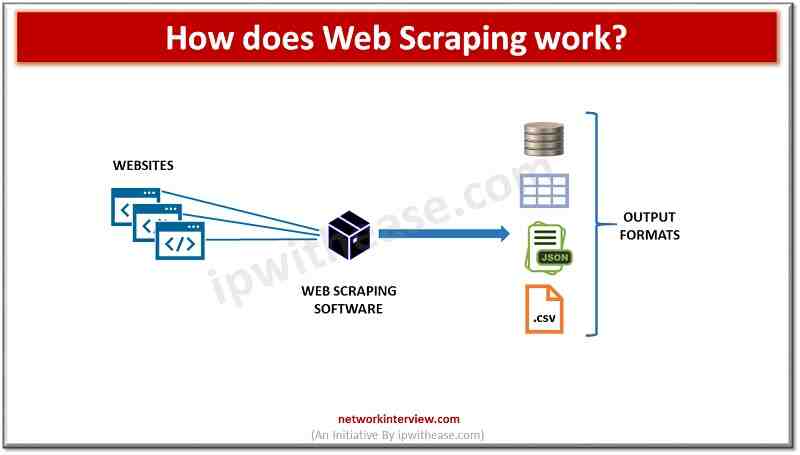
Comment fonctionne le web scraping ?
Le réseau de grattage consiste à extraire des données de pages Web et à les enregistrer pour analyse ou utilisation d’une autre manière. le grattage permet de collecter des informations comportementales très différentes.
Est-ce que le scraping est légal ?
L’activité de grattage n’est donc pas illégale, en revanche la réutilisation des données grattées, au fur et à mesure d’un petit changement, présente de nombreux risques et devrait faire l’objet d’une étude juridique détaillée portant sur le niveau de variabilité des données collectées.
Quel langage pour web scraping ?
Python est le langage le plus populaire pour la navigation Web car il peut facilement gérer la plupart des tâches.
Comment faire du Web scraping en python ?
Voici les étapes clés pour explorer votre site à l’aide de Python :
- Trouvez l’URL du site à gratter.
- Naviguer sur la page
- Trouvez les données que vous souhaitez extraire.
- Demandez un bloc-notes.
- Rédaction et traitement des données.
- Stockez les données dans le format requis.
Comment faire du Web scraping ?
Le principe du web crawling ou crawling se fait en deux temps : l’import, le code HTML d’une page à scraper, et son analyse. Pour trouver le contenu du site (télécharger) il suffit de faire une application et HTTP et d’attendre la réponse (Oui c’est facile).
Où Peut-on récupérer les données publiques dans le but de les exploiter ?

La méthode la plus courante d’extraction de données juridiques consiste à identifier et à extraire des données publiques diffusées sous licence libre et ouverte. Compte tenu de la grande quantité de données disponibles sur les jeux ouverts sur data.gouv.fr, des licences liées à des données réutilisables apparaissent.
Où pouvons-nous extraire les données publiques aux fins prévues ? 10 sites de référence pour l’open data
- www.data.gov – référence. …
- data.gouv.fr – Version française. …
- ouvert.canada.ca – Données publiques canadiennes. …
- data.gov.uk – Données ouvertes au Royaume-Uni. …
- data.europa.eu – Union européenne.
Est-ce que le scraping est légal ?
L’activité de grattage n’est donc pas illégale, en revanche la réutilisation des données grattées, au fur et à mesure d’un petit changement, présente de nombreux risques et devrait faire l’objet d’une étude juridique détaillée portant sur le niveau de variabilité des données collectées.
Comment fonctionne le Web scraping ?
Le réseau de grattage consiste à extraire des données de pages Web et à les enregistrer pour analyse ou utilisation d’une autre manière. le grattage permet de collecter des informations comportementales très différentes.
Qui utilise le scraping ?
Le crawling Web est utilisé par de nombreuses entreprises numériques dédiées à la collecte de données. Pour mieux définir ce qu’est l’exploration Web, vous devez savoir quels sont les cas d’utilisation légitimes : les robots des moteurs de recherche explorent le site, analysent son contenu, puis le classent.