Comment crawler un site web ?

Le terme indexation de site signifie numériser ou visualiser une page et extraire autant d’informations que possible. Le but de l’indexation est de connaître la structure de la page et d’avoir exactement la même vision que Google. Cela permet notamment : l’identification de problèmes avec la structure de l’arbre.
Comment indexer un site ? SEO : comment améliorer l’indexation de votre site en 3 étapes
- Trouvez les pages qui dépensent votre indexation budgétaire. …
- Dirigez les robots vers les bonnes pages. …
- Éloignez les robots des pages qui ne doivent pas être indexées.
Comment fonctionne le crawler ?
Comment fonctionne un crawler ? Les robots d’exploration peuvent être programmés pour indexer le Web à des fins spécifiques. Ils sont toujours actifs et visitent le site selon les instructions qui leur sont données.
Quels éléments du site Google ne doit pas crawler ?
Crawl ne voit pas les backlinks : il ne peut pas considérer l’impact des backlinks car il ne voit pas les pages qui renvoient vers votre page. Crawl ne peut pas voir les pages qui ne sont pas liées dans la structure de votre page (pages sans parent).
Pourquoi crawler un site ?
Le but de l’indexation est de connaître la structure de la page et d’avoir exactement la même vision que Google. Cela permet notamment : l’identification de problèmes avec la structure de l’arbre. trouver des problèmes de réseautage interne (mauvaise répartition de la popularité, existence de pages pièges, existence de liens morts, etc.)
Quels éléments du site Google ne doit pas crawler ?
Crawl ne voit pas les backlinks : il ne peut pas considérer l’impact des backlinks car il ne voit pas les pages qui renvoient vers votre page. La recherche ne peut pas voir les pages qui ne sont pas liées dans la structure de votre site Web (pages sans parent).
Comment Google crawl ?
Comment la recherche Google organise les informations. Avant même de saisir votre requête, les moteurs de recherche collectent des informations sur des centaines de milliards de pages Web et les organisent dans un index de recherche Google.
Pourquoi crawler un site ?
Le but de l’indexation est de connaître la structure de la page et d’avoir exactement la même vision que Google. Cela permet notamment : l’identification de problèmes avec la structure de l’arbre. trouver des problèmes de réseautage interne (mauvaise répartition de la popularité, existence de pages pièges, existence de liens morts, etc.)
Quels éléments du site Google ne doit pas crawler ?
Crawl ne voit pas les backlinks : il ne peut pas considérer l’impact des backlinks car il ne voit pas les pages qui renvoient vers votre page. La recherche ne peut pas voir les pages qui ne sont pas liées dans la structure de votre site Web (pages sans parent).
Comment fonctionne un crawler ? Comment fonctionne un crawler ? Les robots d’exploration peuvent être programmés pour indexer le Web à des fins spécifiques. Ils sont toujours actifs et visitent le site selon les instructions qui leur sont données.
Comment Google crawl ?
Comment la recherche Google organise les informations. Avant même de saisir votre requête, les moteurs de recherche collectent des informations sur des centaines de milliards de pages Web et les organisent dans un index de recherche Google.
Pourquoi demander une indexation Google ?
Sélectionnez Demande d’indexation. L’outil exécute un test en direct sur l’URL pour déterminer si elle présente des problèmes d’indexation évidents. S’il n’y a pas de problème, la page est mise en attente d’indexation. Si l’outil détecte des problèmes sur la page, essayez de les résoudre.
Comment fonctionne les robots de Google ?
Google utilise un grand nombre d’ordinateurs pour aider son robot à rechercher des milliards de sites Web en même temps. Le robot s’appuie sur des algorithmes : les programmes informatiques déterminent les sites à indexer, à quelle fréquence et le nombre de pages à rechercher sur chaque page.
Pourquoi crawler un site ?
Le but de l’indexation est de connaître la structure de la page et d’avoir exactement la même vision que Google. Cela permet notamment : l’identification de problèmes avec la structure de l’arbre. trouver des problèmes de réseautage interne (mauvaise répartition de la popularité, existence de pages pièges, existence de liens morts, etc.)
Comment s’appelle le processus Crawling ?
C’est ce qu’on appelle Google Crawl, l’indexation Web, l’indexation du navigateur ou l’indexation générale. Creeping est donc un processus de recherche de sites web pour les classer selon leur pertinence. Les moteurs de recherche Google, ou index, s’en chargent.
Comment copier la ligne indiquant au moteur de recherche de ne pas référencer la page ?
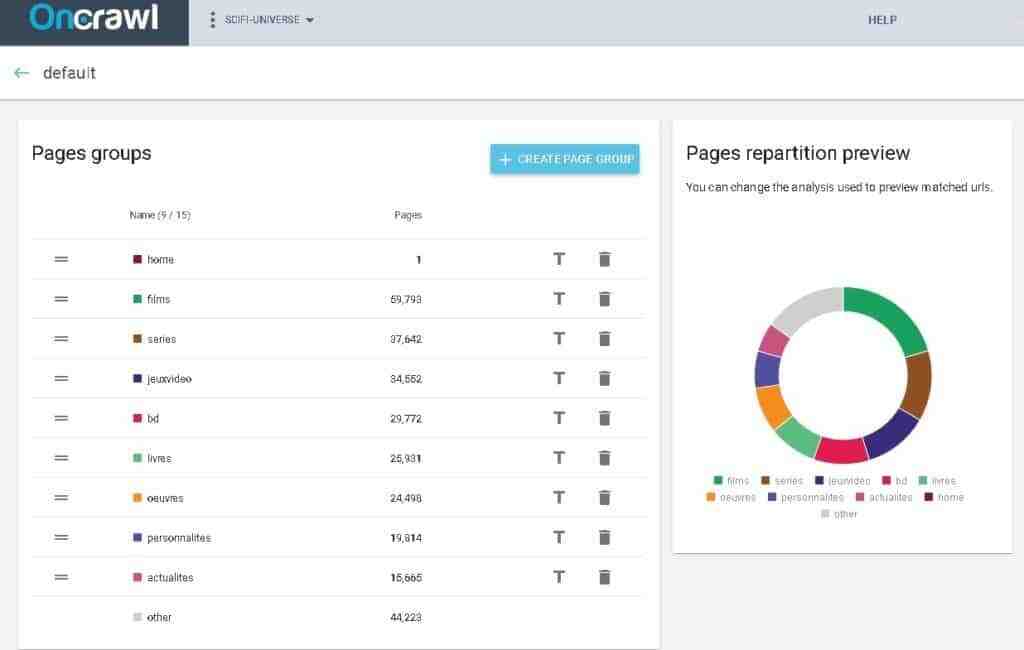
message. Fondamentalement, c’est un fichier texte qui indique aux moteurs de recherche de ne pas indexer certaines pages. Vous n’êtes pas obligé de l’inclure dans l’en-tête de votre page ; Tant qu’il se trouve dans le répertoire racine de votre site Web, il sera récupéré par les moteurs de recherche.
Pourquoi ne pas indexer la page ? Ainsi, ne pas indexer certaines pages signifie que vous envoyez un message aux moteurs de recherche indiquant que ces pages ne sont pas importantes et n’apportent rien. Lorsque Google recevra ces informations, il les prendra en compte dans ces critères de popularité et de notoriété de votre site.
Pourquoi mon site n’apparaît pas dans la recherche Google ?
Si votre page ou votre page est nouvelle, il se peut qu’elle ne figure pas dans notre index car nous n’avons pas encore été en mesure de l’indexer ou de l’indexer. … Si vous avez récemment migré votre site vers la version HTTPS, assurez-vous que vos URL HTTP et HTTPS sont présentes dans Google.
Pourquoi mon site Wix n’apparaît pas sur Google ?
Vous ne pouvez pas apparaître sur Google si vous avez intentionnellement bloqué les moteurs de recherche. … Allez dans votre éditeur Wix et allez dans la gestion des pages, puis pour chaque page vérifiez dans les paramètres de référence qu’elles ne sont pas bloquées pour les moteurs de recherche.
Pourquoi je ne trouve pas mon site ?
Avant que votre site Web puisse apparaître dans les résultats de recherche Google, vous devez d’abord informer Google de son existence. Pour ce faire, Google dispose de robots d’exploration appelés crawlers, qui explorent et indexent les sites.
Comment faire pour ne pas referencer une page ?
Parmi les valeurs les plus couramment utilisées : « all », donnant un accès complet aux robots ; « noindex », interdiction d’indexation ; « nofollow », qui ne transmet pas de liens ; et « noarchive », empêchant ces pages d’être archivées par des machines.
Comment ne pas être référencé ?
Pour éloigner les robots moteurs de leurs sites, plusieurs solutions existent : les robots. txt, contrôle d’accès au serveur, utilisation de balises, implémentation Javascript. Chaque besoin a sa propre méthode.
Comment savoir qu’une page n’est pas référence ?
Une technique très simple consiste à saisir une information dans un moteur de recherche : « l’url de votre site ». Si Google voit votre page, c’est parce qu’elle est indexée et donc référencée.
Comment copier la ligne indiquant aux moteurs de recherche de ne pas la référencer ?
Pour ce faire, cliquez avec le bouton droit sur le lien des résultats et sélectionnez « copier l’adresse du lien ». Motivez votre demande en indiquant au moteur de recherche pourquoi vous souhaitez que ce lien soit déréférencé.
Comment ne pas faire référencer une page ?
Vous pouvez empêcher une page ou une autre ressource d’apparaître dans la recherche Google en incluant une balise Meta ou un en-tête noindex dans votre réponse HTTP.
Comment ne pas être référencé ?
Pour éloigner les robots moteurs de leurs sites, plusieurs solutions existent : les robots. txt, contrôle d’accès au serveur, utilisation de balises, implémentation Javascript. Chaque besoin a sa propre méthode.
Quelle est la fonction d’un moteur de recherche ?
Définition du mot Moteur de recherche Le moteur de recherche, comme son nom l’indique, est un outil qui permet de rechercher sur le Web (mais aussi sur un ordinateur personnel) des ressources, des contenus, des documents, etc., à partir de mots-clés.
La recherche est-elle facile ? Les moteurs de recherche fonctionnent en trois phases. Tout d’abord, un crawl qui consiste en des robots effectuant des recherches sur le Web pour collecter des informations sur des pages Web. Ensuite, c’est l’indexation : les données sont analysées et classées dans des bases de données pour permettre leur exploitation.
Quel est l’importance des moteurs de recherche ?
Le rôle d’un moteur de recherche est très simple : aider les utilisateurs à trouver la réponse la plus pertinente à leur requête. Aujourd’hui, les moteurs de recherche sont devenus incontournables. En effet, ils aident les internautes à trouver facilement et très rapidement une grande quantité d’informations.
Quelle est l’utilité d’un moteur de recherche ?
Un navigateur est, comme son nom l’indique, un outil qui permet de rechercher sur le Web (mais aussi sur un ordinateur personnel) des ressources, des contenus, des documents, etc., à l’aide de mots-clés.
Quels sont les avantages d’un moteur de recherche ?
Les moteurs de recherche d’entreprise sont essentiels pour les organisations car ils les aident à améliorer leur productivité en fournissant un accès rapide et opportun à de grands ensembles de données. La technologie des moteurs de recherche a évolué au fil des ans.
Quelles sont les trois missions d’un moteur de recherche ?
Les navigateurs Web intéressants lors de l’optimisation ont trois fonctions de base : Rechercher des sites ou des pages Web sur Internet (pas encore dans la base de données) à l’aide de robots, indexer des sites et/ou des pages Web selon une certaine logique, appelée algorithme, et mettre. ..
C’est quoi le moteur de recherche ?
Un moteur de recherche est un logiciel qui vous permet de trouver les informations que vous souhaitez en ligne à l’aide de mots-clés ou d’expressions. … Les moteurs de recherche les plus populaires sont Google, Bing et Yahoo.
C’est quoi le moteur de recherche ?
Un moteur de recherche est un logiciel qui vous permet de trouver les informations que vous souhaitez en ligne à l’aide de mots-clés ou d’expressions. … Les moteurs de recherche les plus populaires sont Google, Bing et Yahoo.